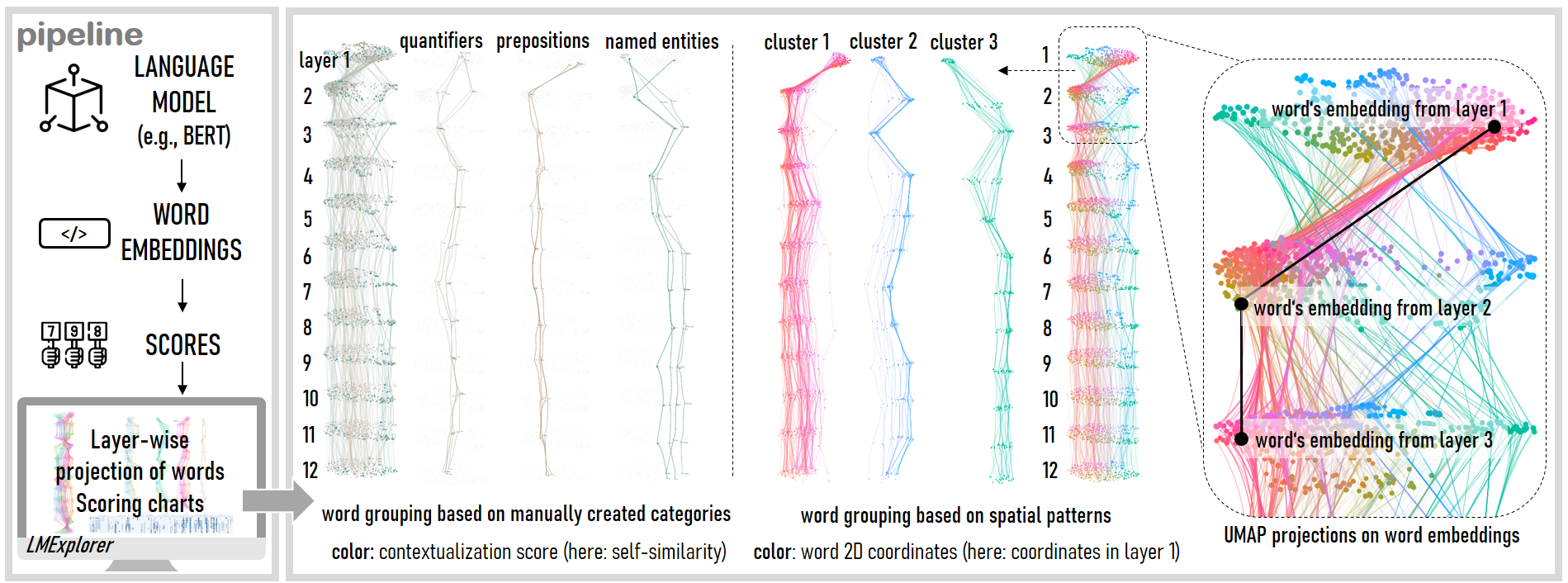
Project Description
Our research focuses on exploring contextualization in Transformer models such as BERT. Our goal is to investigate to which degree the model captures semantic and syntactic context information. We focus on analyzing the contextualization through diverse scoring techniques and by comparing word embeddings with their nearest neighborhoods. To gain more detailed insights into how the model learns and captures the word contexts, we make our observations layer-wise, i.e., we explain the degree of contextualization for each layer of the model separately.
Explaining Contextualization through Word Self-Similarity
To explain contextualization in deep learning models, we first need to extract contextualized word embeddings for each word's surrounding context (e.g., sentence). To gain deeper insights into how the model learns the context information, we extract the embeddings layer-wise (e.g., from 12 layers of BERT-base model).
Computing aggregated word embeddings
As exemplified here, each word is represented by as many contextualized word embeddings as in many contexts it occurs in the corpus. For the visualization purposes, we compute an aggregated word embedding that we use as a singe word's representation. We compute the aggregated embedding either by averaging the single context embeddings or selecting the median among the context-level embeddings.
Computing contextualization scores
As shown by Ethayarajh (2019), statistical measures such as word self-similarity can be used to describe the degree of word contextualization. Self-similarity is defined as "the average cosine similarity of a word with itself across all the contexts in which it appears, where representations of the word are drawn from the same layer of a given model." We compute the self similarity score for all words in the corpus.
Reducing the dimensionality to 2D
We use the aggregated word embedding as a word's representation for visualization purposes. To enable the exploration of spatial patterns, we use a dimensionality reduction technique on the aggregated embedding vectors from each layer of the language model. In particular, we reduce the 768-dimensional embedding vectors to two dimensions, used as x and y coordinates to visualize words in one layer. Using this technique, words with similar embeddings are represented by similar coordinates in the 2D space. We create such a projection for each model's layer. Since the embeddings extracted from different layers usually differ, the word positions in the 2D space of different layers may differ as well. Hence, in different layers, words may get surrounded by new neighborhoods. We compute these projections for all layers of the model (i.e., 12 layers for BERT-base model).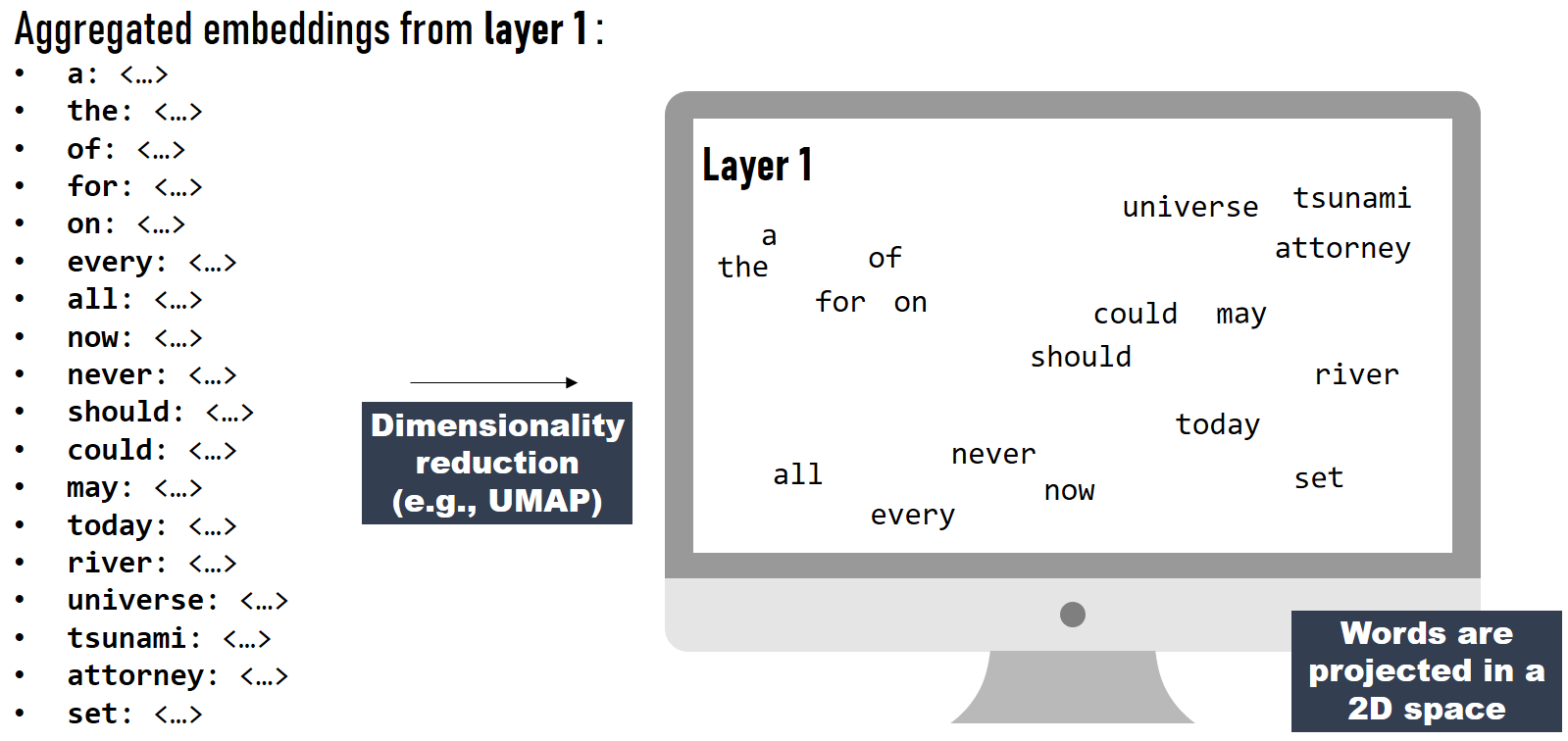
Building interlinked projections
Projection-based visualizations are the most common methods to visualize word embeddings (e.g., Smilkov et al., 2016; Liu et al., 2017; van Aken et al., 2019; van Aken et al.,202019) and although some approaches have enabled the exploration of embeddings in different layers (e.g., Smilkov et al., 2016; van Aken et al., 2019; van Aken et al.,202019), they typically visualize only one layer of the model at a time. However, changes in embedding positions and their neighborhoods across layers can be an indicator of the model capturing new context information. To support such analyses, our technique displays the embeddings for all layers of the LM simultaneously and visually highlights changes in their neighborhoods.In total, 12 projections are created, each representing one layer of the BERT-base model.
The projections are ordered vertically underneath each other, starting from layer one at the very top and ending with the last layer at the bottom.
The words in the projection are visualized as shapes. By default, they are displayed as circles. We can use the computed self-similarity scores to specify word colors.
After displaying the projections, we add connecting lines between layers to support the analysis of word position changes in the visualized space. Changes in the word position in the 2D space might indicate that the model captures a new meaning of the word.
To reduce the number of crossing edges, we additionally apply an edge-bundling technique that combines neighboring edges for words that remain in the same neighborhood in two consecutive layers in a more coherent representation.


Supporting corpus exploration
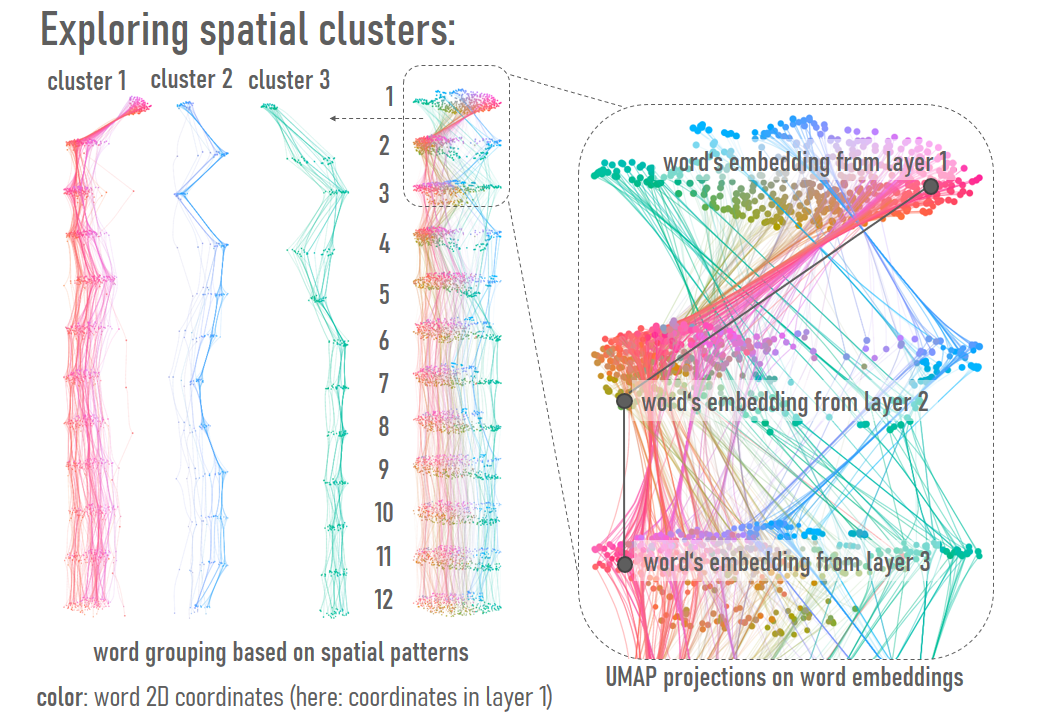
The users can explore the embeddings in different layers, and filter words by their self-similarity scores. Words that fit the selected self-similarity range for a particular layer are grouped and highlighted, letting the users to comprehend on whether words with similar score patterns are located in a close neighborhood. That would indicate that words with similar self-similarity scores have similar embeddings.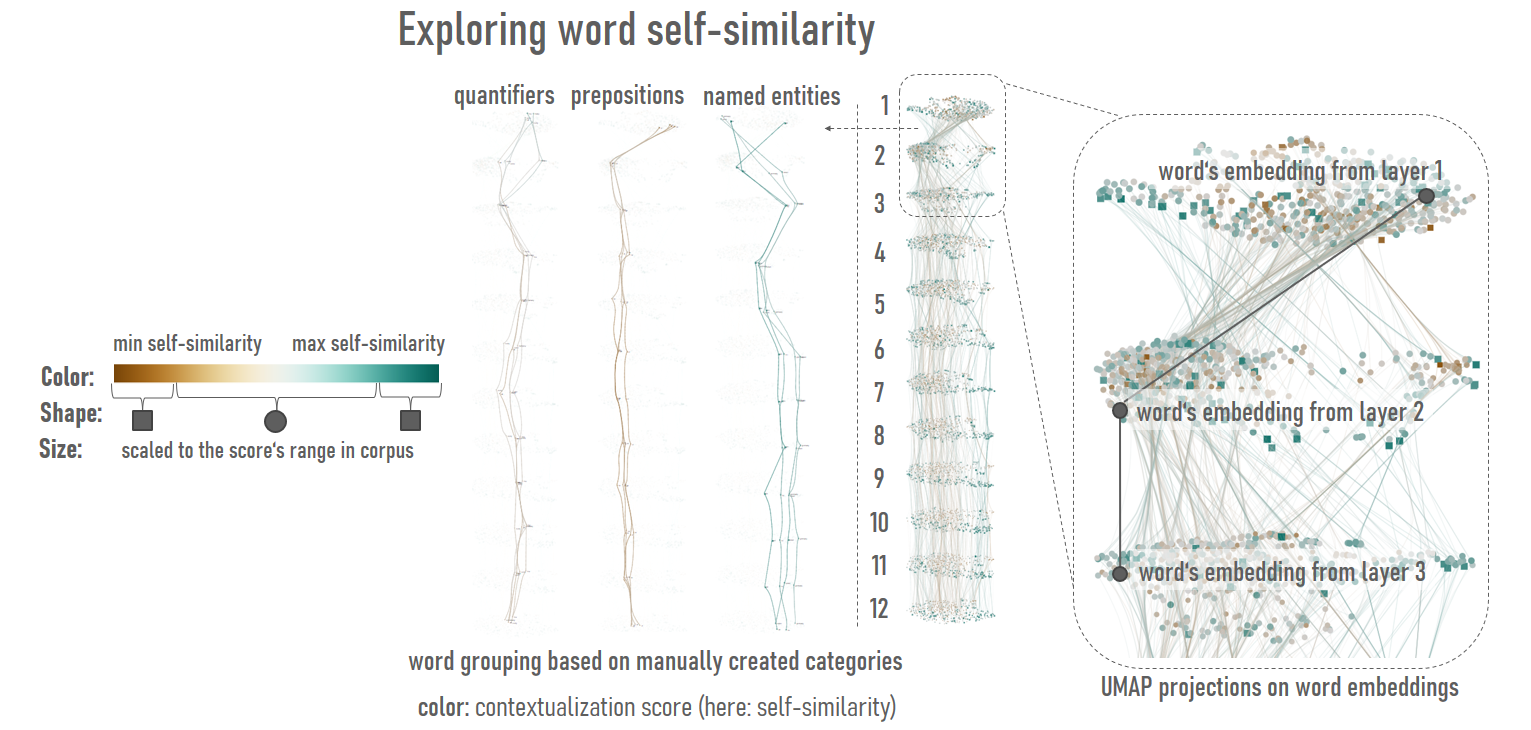 Alternatively, words can be colored according to the word’s position in the 2D space.
A word in all projections gets assigned a unique color, which represents its position in
the 2D space in the reference layer. To specify the color, we use the LAB color space
(please, see El-Assady et al. (2019) for more details).
This representation helps in analyzing word neighborhood changes.
Alternatively, words can be colored according to the word’s position in the 2D space.
A word in all projections gets assigned a unique color, which represents its position in
the 2D space in the reference layer. To specify the color, we use the LAB color space
(please, see El-Assady et al. (2019) for more details).
This representation helps in analyzing word neighborhood changes.
 To support even more detailed exploration of the changes in word self-similarity score, we designed an additional matrix-based visualization where a word is represented as a column on the screen.
There, the 12 shapes represent the 12 self-similarity values, each extracted from one layer of the BERT-base model.
To support even more detailed exploration of the changes in word self-similarity score, we designed an additional matrix-based visualization where a word is represented as a column on the screen.
There, the 12 shapes represent the 12 self-similarity values, each extracted from one layer of the BERT-base model.
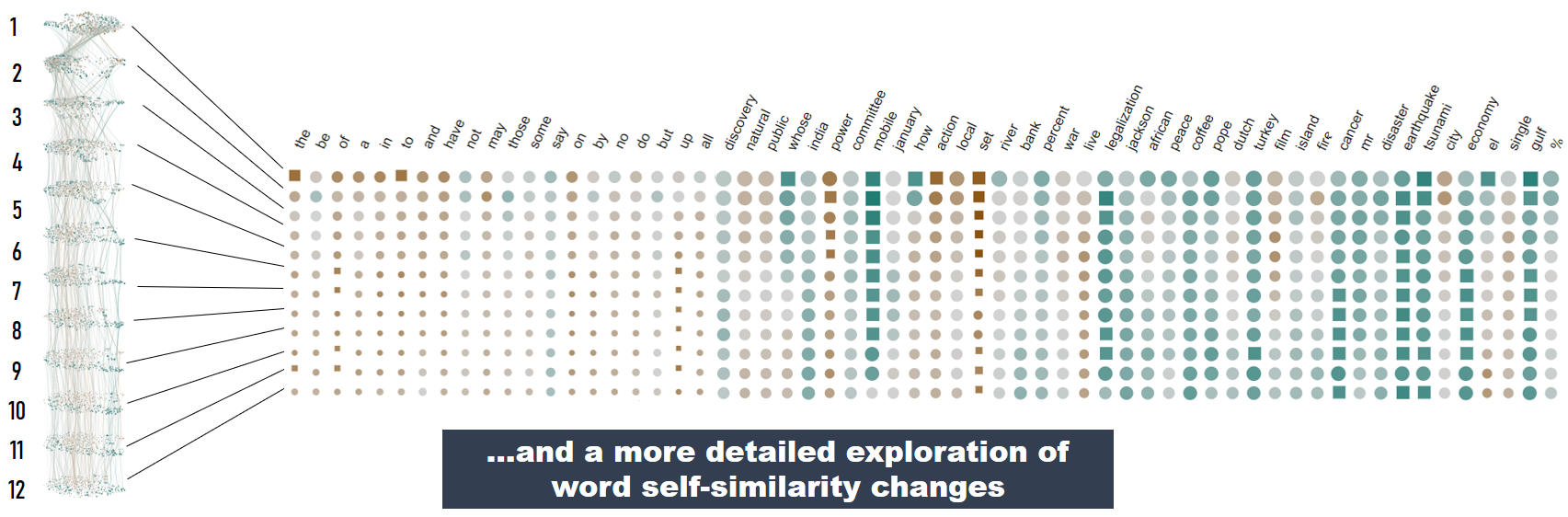 The users can query for words with similar score patterns; these are highlighted in the different visualizations for a more detailed analysis.
The users can query for words with similar score patterns; these are highlighted in the different visualizations for a more detailed analysis.

Taking a closer look at word self-similarity
Data
In this work, we visualize a random subset of 800 unique sentences of the RTE-1 (Dagan et al., 2005), RTE-2 (Bar-Haim et al., 2006) and RTE-3 (Giampiccolo et al., 2007) corpora. These corpora contain sentence pairs originally intended for Natural Language Inference. They stem from the news domain and thus contain variable content. The pairs are split into single sentences and mapped to their POS tags based on the Stanford POS tagger (Toutanova et al., 2003). We visualize the BERT-base embeddings and self-similarity of 496 unique words with a frequency greater than 5 and lower than 50.Treating functionality as continuum
By observing words in the corpus, one can easily recognize that not all words have the same degree of contextualization. In particular, we can see words where the self-similarity score stays in the max-range throughout the model’s layers, however other words, for instance, stopwords, are highly contextualized. The current literature suggests that there might be two “patterns” for word contextualization. First, it has been suggested that deep learning based language models such as BERT capture the polysemy of words. If that is true, we would expect as many contextualized word embeddings as many meaning a word has. However, this assumption does not fit to the observations made for stop-words. Stop-words are not polysemous in a semantic sense, however they still have a high contextualization. Thus, contextualization seems not to be entirely driven by polysemy, but rather the variety of contexts a word appears in (Ethayarajh, 2019). However, function words are not a homogeneous class, and some function words indeed have semantic content in addition to having a grammatical function. Thus, we decided to investigate function and content words in more detail, using the LMExplorer to explore contextualization in BERT with respect to the functionality continuum.Remark: Here, scores are normalized globally (over all layers)!
Observations
Using LMExplorer, we grouped words according to different linguistic categories and explored their self-similarity score patterns.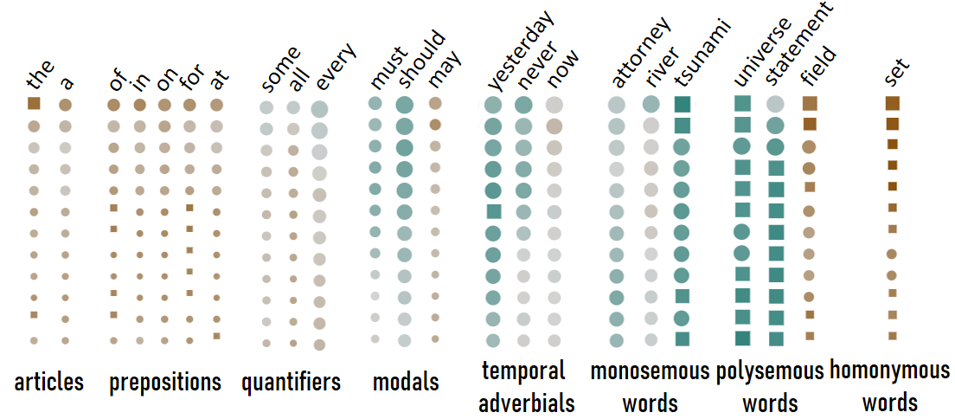
Functionality continuum
During our exploration, we came across patterns that fit to the theory of the functionality continuum and others that were contrary to our expectations. Above all, we observed that contextualization is neither triggered merely by polysemy nor by variation in context. To explain the observed patterns, a) we positioned the defined categories within the functionality continuum based on the inherent linguistic properties of the words and on insights from lexical semantics, and b) we identified three criteria as potential triggers of contextualization. The first criterion refers to the sense variation (Sense Var.), i.e., whether a word has multiple senses (high variation), or only one or multiple but very closely related senses (low variation). The second criterion captures syntactic context variation (SynCtx. Var.), i.e., whether a word needs to be part of a specific syntactic structure (low) or is flexible in terms of attachment and can be found in different kinds of syntactic structures (high). Another potential trigger we identified is that of variation of semantic context (SemCtx. Var.). This captures whether the contexts in which a word can occur are semantically similar (low) or different (high) to one another. Based on these triggers and previous findings on contextualization by Ethayarajh (2019), we derive the expected contextualization (Exp. Contextual.) of each of the predefined categories. We can then compare this to BERT’s actual behavior (BERT) and shed light on BERT’s abilities to capture the functionality continuum.Insights
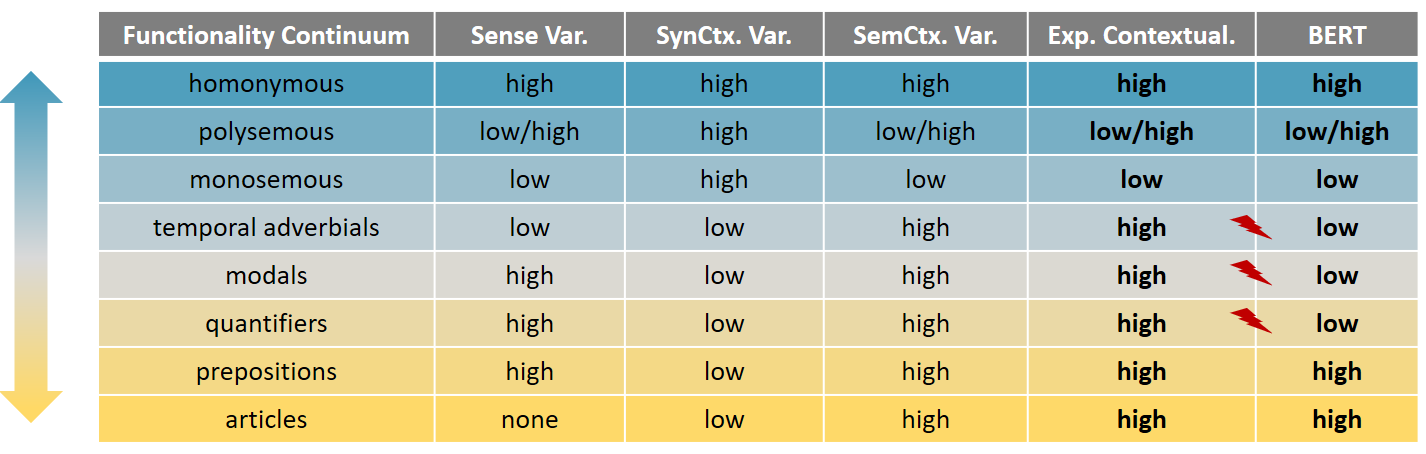 We see that BERT struggles to efficiently capture the functionality continuum.
While BERT manages to model the ends of the continuum, i.e., the mostly content and
mostly functional words, it fails to create expressive embeddings for categories with
content as well as functional properties. This finding is in line with previous
literature that has shown that current language models cannot efficiently capture hard linguistic
phenomena (e.g., Dasgupta et al. (2018);
McCoy et al. (2019);
Richardson et al. (2020)),
with modals, quantifiers and temporal reasoning belonging to these phenomena.
Our work suggests that the BERT embeddings are not specific enough to capture
the inherent functionality of certain word types, i.e.,
BERT does not learn the relevant generalizations.
Additionally, we show that contextualization is neither entirely driven by polysemy nor
context variation. Rather, contextualization can be explained via the harmonical
combination of functionality, sense variation, syntactic variation and semantic
context variation: BERT can efficiently model polysemy, homonymy and mononymy, i.e.,
it can efficiently capture words that appear in semantic contexts of high variation and
low variation and 4We treat determiners as definiteness markers, rather than
as quantifiers or discourse markers, to be in-line with their treatment in popular NLP tasks such as NLI.
independently of their polysemy. What it cannot model are words that have a
semi-functional/semi-content nature (modals, quantifiers, temporal adverbials).
Overall, BERT seems to follow findings of psycholinguistics and language acquisition:
children learn content words easier and earlier than function words
(Bates et al., 1994;
Caselli et al., 1995). Drawing from language acquisition research,
we see an opportunity for explainable methods to inspect BERT’s inner-workings and
improve its linguistic understanding, raising LMs from their infantile state to a more
linguistically-mature one.
We see that BERT struggles to efficiently capture the functionality continuum.
While BERT manages to model the ends of the continuum, i.e., the mostly content and
mostly functional words, it fails to create expressive embeddings for categories with
content as well as functional properties. This finding is in line with previous
literature that has shown that current language models cannot efficiently capture hard linguistic
phenomena (e.g., Dasgupta et al. (2018);
McCoy et al. (2019);
Richardson et al. (2020)),
with modals, quantifiers and temporal reasoning belonging to these phenomena.
Our work suggests that the BERT embeddings are not specific enough to capture
the inherent functionality of certain word types, i.e.,
BERT does not learn the relevant generalizations.
Additionally, we show that contextualization is neither entirely driven by polysemy nor
context variation. Rather, contextualization can be explained via the harmonical
combination of functionality, sense variation, syntactic variation and semantic
context variation: BERT can efficiently model polysemy, homonymy and mononymy, i.e.,
it can efficiently capture words that appear in semantic contexts of high variation and
low variation and 4We treat determiners as definiteness markers, rather than
as quantifiers or discourse markers, to be in-line with their treatment in popular NLP tasks such as NLI.
independently of their polysemy. What it cannot model are words that have a
semi-functional/semi-content nature (modals, quantifiers, temporal adverbials).
Overall, BERT seems to follow findings of psycholinguistics and language acquisition:
children learn content words easier and earlier than function words
(Bates et al., 1994;
Caselli et al., 1995). Drawing from language acquisition research,
we see an opportunity for explainable methods to inspect BERT’s inner-workings and
improve its linguistic understanding, raising LMs from their infantile state to a more
linguistically-mature one.